对比redux和mobx
我们知道,现有的状态框架,主要有两大类型,一个是redux为代表的基于对数据订阅的模式来做状态全局管理,一种是以mobx为代表的将数据转变为可观察对象来做主动式的变更拦截以及状态同步。
vs redux
我们先聊一聊redux,这个当前react界状态管理的一哥。
redux难以言语的reducer
写过redux的用户,或者redux wrapper(如dva、rematch等)的用户,都应该很清楚 redux的一个约定:reducer必需是纯函数,如果状态改变了,必需解构原state返回一个新的state
// fooReducer.js
export default (state, action)=>{
switch(action.type){
case 'FETCH_BOOKS':
return {...state, ...action.payload};
default:
return state;
}
}
纯函数没有副作用,容易被测试的特点被提起过很多次,我们写着写着,对于actionCreator和reducer,有了两种流派的写法,
- 一种是将异步的请求逻辑以及请求后的数据处理逻辑,都放在
actionCreator写完了,然后将数据封装为payload,调用dispatch, 讲数据派发给对应的reducer。
此种流派代码,慢慢变成
reducer里全是解构payload然后合成新的state并返回的操作,业务逻辑全部在actionCreator里了,此种有一个有一个严重的弊端,因为业务逻辑全部在actionCreator里,reducer函数里的type值全部变成了一堆类似CURD的命名方式,saveXXModel、updateXXModelXXField、setXXX、deleteXXX等看起来已经和业务逻辑全然没有任何关系的命名,大量的充斥在reducer函数里,而我们的状态调试工具记录的type值恰恰全是这些命名方式,你在调试工具里看到变迁过程对应的type列表,只是获取到了哪些数据被改变了的信息,但全然不知这些状态是从哪些地方派发了payload导致了变化,甚至想知道是那些UI视图的什么交互动作导致了状态的改变,也只能从代码的reducer的type关键字作为搜索条件开始,反向查阅其他代码文件。
- 还有一种是让
actionCreator尽可能的薄,派发同步的action就直接return,异步的action使用thunk函数或者redux-saga等第三方库做处理,拿到数据都尽可能早的做成action对象,派发到reducer函数里,
此种模式下,我们的
actionCreator薄了,做的事情如其名字一样,只是负责产生action对象,同时因为我们对数据处理逻辑在reducer里了,我们的type值可以根据调用方的动机或者场景来命名了,如formatTimestamp、handleNameChanged、handelFetchedBasicData等,但是由于redux的架构导致,你的ui触发的动作避免不了的要要经过两个步骤,一步经过actionCreator生成action,第2步进过经过reducer处理payload合成新的state,所以actionCreator的命名和reducerType的命名通常为了方便以后阅读时能够带入上下文信息很有可能会变成一样的命名,如fetchProductList,在actionCreator里出现一遍,然后在reducerType又出现一遍
concent化繁为简的reducer
concent里reducer担任的角色就是负责返回一个新的片段视图,所以你可以认为它就是一个partialStateGenerator函数,你可以声明其为普通函数
//code in fooReducer.js
function fetchProductList(){
}
也可以是async函数或者generator函数
async function fetchProductList(){
}
如果,你的函数需要几步请求才能完成全部的渲染,但是每一步都需要及时触发视图更新,concent允许你自由组合函数,如果同属于一个模块里的reducer函数,相互之间还可以直接基于函数签名来调用
function _setProductList(dataList){
return {dataList};
}
//获取产品列表计基础数据
async function fetchProductBasicData(payload, moduleState, ctx){
const dataList = await api.fetchProductBasicData();
return {dataList};//返回数据,触发渲染
// or ctx.dispatch(_setProductList, dataList);
}
//获取产品列表计统计数据,统计数据较慢,分批拉取 (伪代码)
async function fetchProductStatData(payload, moduleState, ctx){
const dataList = moduleState.dataList;
//做分批拉取统计数据的ids,逻辑略......
const batchIdsList = [];
const len = batchIds.length;
for(let i=0; i<len; i++){
const ids = batchIdsList[i];
const statDataList = await api.fetchProductBasicData(ids);
//逻辑略...... 游标开始和结束,改变对应的data的统计数据
let len = statDataList.length;
for(let j=0; j<len; j++){
dataList[j+cursor].stat = statDataList[j];//赋值统计数据
}
await ctx.dispatch(_setProductList, dataList);//修改dataList数据,触发渲染
}
}
//一个完整的产品列表既包含基础数据、也包含统计数据,分两次拉取,其中统计数据需要多次分批拉取
async function fetchProductList(payload, moduleState, ctx){
await ctx.dispatch(fetchProductBasicData);
await ctx.dispatch(fetchProductStatData);
}
现在你只需要视图实例里调用$$dispatch触发更新即可
//属于product模块的实例调用
this.$$dispatch('fetchProductList');
//属于其他模块的实例调用
this.$$dispatch('product/fetchProductList');
可以看到,这样的代码组织方式,更符合调用者的使用直觉,没有多余的操作,相互调用或者多级调用,可以按照开发者最直观的思路组织代码,并且很方便后期不停的调整后者重构模块里的reducer。
concent强调返回欲更新的片段状态,而不是合成新的状态返回,从工作原理来说,因为concent类里标记了观察key信息,reducer提交的状态越小、越精准,就越有利于加速查找到关心这些key值变化的实例,还有就是concent是允许对key定义watch和computed函数的,保持提交最小化的状态不会触发一些冗余的watch和computed函数逻辑;从业务层面上来说,你返回的新状态是需要符合函数名描述的,我们直观的解读一段函数时,大体知道做了什么处理,最终返回一个什么新的片段状态给concent,是符合线性思维的^_^,剩下的更新UI的逻辑就交给concent吧。
可能读者留意到了,redux所提倡的纯函数容易测试、无副作用的优势呢?在concent里能够体现吗,其实这一点担心完全没有必要,因为你观察上面的reducer示例代码可以发现,函数有无副作用,完全取决于你声明函数的方式,async(or generator)就是副作用函数,否则就是纯函数,你的ui里可以直接调用纯函数,也可以调用副作用函数,根据你的使用场景具体决定,函数名就是type,没有了actionCreator是不是世界清静了很多?
进一步挖掘reducer本质,上面提到过,对于concent来说,reducer就是partialStateGenerator函数,所以如果讨厌走dispatch流派的你,可以直接定义一个函数,然后调用它,而非必需要放置在模块的reducer定义下。
function inc(payload, moduleState, ctx){
ctx.dispatch('bar/recordLog');//这里不使用await,表示异步的去触发bar模块reducer里的recordLog方法
return {count: moduleState.count +1 };
}
@register('Counter', 'counter')(Counter)
class Counter extends Component{
render(){
return <div onClick={()=> this.$$invoke(inc}>count: {this.state.count}</div>
}
}
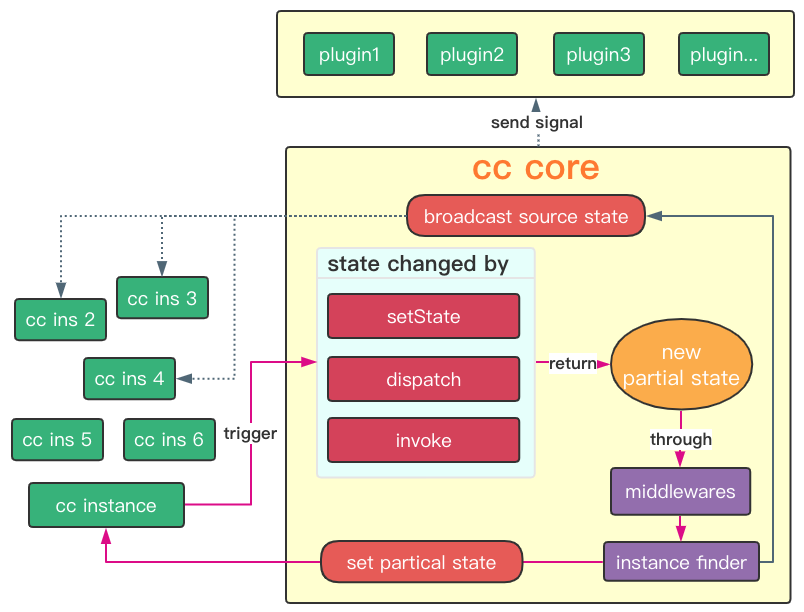
concent不仅书写体验友好,因为concent是以引用收集为基础来做状态管理,所以在concent提供的状态调试工具里可以精确的定位到每一次状态变更提交了什么状态,调用了哪些方法,以及由哪些实例触发。
redux复杂的使用体验
尽管redux核心代码很简单,提供composeReducers、bindActionCreators等辅助函数,作为桥接react的react-redux提供connect函数,需要各种手写mapStateToProps和mapDispatchToProps等操作,整个流程下来,其实已经让代码显得很臃肿了,所以有了dva、rematch等redux wrapper做了此方面的改进,化繁为简,但是无论怎么包装,从底层上看,对于redux的更新流程来说,任何一个action派发都要经过所有的reducer,reducer返回的状态都要经过所有connect到此reducer对应状态上的所有组件,经过一轮浅比较(这也是为什么redux一定要借助解构语法,返回一个新的状态的原因),决定要不要更新其包裹的子组件。
const increaseAction = {
type: 'increase'
};
const mapStateToProps = state => {
return {value: state.count}
};
const mapDispatchToProps = dispatch => {
return {
onIncreaseClick: () => dispatch(increaseAction);
}
};
const App = connect(
mapStateToProps,
mapDispatchToProps
)(Counter);
concent简单直接的上手体验
注册成为concent类的组件,天生就有操作store的能力,而且数据将直接注入state
//Counter里直接可以使用this.$$dispatch('increase')
class Counter extends Component{
render(){
return <div onClick={()=> this.$$dispatch('increase')}>count: {this.state.count}</div>
}
}
const App = register('Counter', 'counter')(Counter);
你可以注意到,concent直接将$$dispatch方法,绑定在this上,因为concent默认采用的是反向继承策略来包裹你的组件,这样产生更少的组件嵌套关系从而使得Dom层级更少。
store的state也直接注入了this上,这是因为从setState调用开始,就具备了将转态同步到store的能力,所以注入到state也是顺其自然的事情。
当然concent也允许用户在实例的state上声明其他非store的key,这样他们的值就是私有状态了,如果用户不喜欢state被污染,不喜欢反向继承策略,同样的也可以写为
class Counter extends Component{
constructor(props, context){
super(props, context);
this.props.$$attach(this);
}
render(){
return(
<div onClick={()=> this.props.$$dispatch('increase')}>
count: {this.props.$$connectedState.counter.count}
</div>
)
}
}
const App = register('Counter', {connect:{counter:'*'}, isPropsProxy:true} )(Counter);
vs mobx
mobx是一个函数响应式编程的库,提供的桥接库mobx-react将react变成彻底的响应式编程模式,因为mobx将定义的状态的转变为可观察对象,所以
用户只需要修改数据,mobx会自动将对应的视图更新,所以有人戏称mobx将react变成类似vue的编写体验,数据自动映射视图,无需显示的调用setState了。
本质上来说,所有的mvvm框架都在围绕着数据和视图做文章,react把单项数据流做到了极致,mobx为react打上数据自动映射视图的补丁,提到自动映射,自动是关键,框架怎么感知到数据变了呢?mobx采用和vue一样的思路,采用push模式来做变化侦测,即对数据getter和setter做拦截,当用户修改数据那一刻,框架就知道数据变了,而react和我们当下火热的小程序等采用的pull模式来做变化侦测,暴露setState和setData接口给用户,让用户主动提交变更数据,才知道数据发生了变化。
concent本质上来说没有改变react的工作模式,依然采用的是pull模式来做变化侦测,唯一不同的是,让pull的流程更加智能,当用户的组件实例创建好的那一刻,concent已知道如下信息:
- 实例属于哪个模块
- 实例观察这个模块的哪些key值变化
- 实例还额外连接其他哪些模块
同时实例的引用将被收集到并保管起来,直到卸载才会被释放。
所以可以用0改造成本的方式,直接将你的react代码接入到concent,然后支持用户可以渐进式的分离你的ui和业务逻辑。
需要自动映射吗
这里我们先把问题先提出来,我们真的需要自动映射吗?
当应用越来越大,模块越来越多的时候,直接修改数据导致很多不确定的额外因素产生而无法追查,所以vue提供了vuex来引导和规范用户在大型应用的修改状态的方式,而mobx也提供了mobx-state-tree来约束用户的数据修改行为,通过统一走action的方式来让整个修改流程可追查,可调试。
改造成本
所以在大型的应用里,我们都希望规范用户修改数据的方式,那么concent从骨子里为react而打造的优势将体现出来了,可以从setState开始享受到状态管理带来的好处,无需用户接入更多的辅助函数和大量的装饰器函数(针对字段级别的定义),以及完美的支持用户渐进式的重构,优雅的解耦和分离业务逻辑与ui视图,写出的代码始终还是react味道的代码。
结语
concent围绕react提供一种了更舒适、更符合阅读直觉的编码体验,同时新增了更多的特性,为书写react组件带来更多的趣味性和实用性,不管是传统的class流派,还是新兴的function流派,都能够在concent里享受到统一的编码体验。
依托于concent的以下3点核心工作原理:
- 引用收集
- 观察key标记
- 状态广播
基于引用收集和观察key标记,就可以做到热点更新路径缓存,理论上来说,某一个reducer如果返回的待更新片段对象形状是不变的,初次触发渲染的时候还有一个查找的过程(尽管已经非常快),后面的话相同的reducer调用都可以直接命中并更新,有点类似v8里的热点代码缓存,不过concent缓存的reducer返回数据形状和引用之间的关系,所以应用可以越运行越快,尤其是那种一个界面上百个组件,n个模块的应用,将体现出更大的优势,这是下一个版本concent正在做的优化项,为用户带来更快的性能表现和更好的编写体验是concent始终追求的目标。
喜欢的concent的话,给个star吧^_^